| CPC G06T 13/205 (2013.01) [G06N 3/049 (2013.01); G06T 13/40 (2013.01); G06V 40/10 (2022.01); G10L 13/04 (2013.01)] | 20 Claims |
|
1. A method for obtaining a photo-realistic video of a talking person from a text, comprising:
providing, by a computing device, the text for generating the photo realistic video and an image of the talking person;
synthesizing a speech audio from the text;
extracting an acoustic feature from the speech audio by an acoustic feature extractor, wherein the acoustic feature is independent from speaker of the speech audio; and
generating the photo-realistic video from the acoustic feature and the image of the talking person by a video generation neural network,
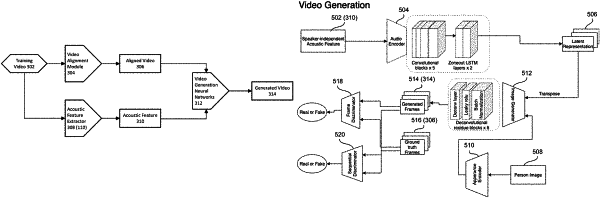
wherein the video generating neural network is pre-trained by:
providing a training video of a training talking person and a training image of the training talking person, wherein the training video comprises a plurality of training video frames and a corresponding training audio;
extracting a training acoustic feature from the training audio by the acoustic feature extractor;
generating a plurality of video frames from the training image and the training acoustic feature by the video generation neural network; and
comparing the generated video frames with ground truth video frames using generative adversarial network (GAN), wherein the ground truth video frames correspond to the training video frames.
|
|
11. A system for generating a photo-realistic video of a talking person from a text, wherein the system comprises a computing device, the computing device comprises a processor and a storage device storing computer executable code, the computer executable code comprises an acoustic feature extractor and a video generation neural network, and the computer executable code, when executed at the processor, is configured to:
provide the text for generating the photo-realistic video and an image of the talking person;
synthesize a speech audio from the text;
extract an acoustic feature from the speech audio by the acoustic feature extractor, wherein the acoustic feature is independent from speaker of the speech audio; and
generate the photo-realistic video from the acoustic feature and the image of the talking person by the video generation neural network,
wherein the video generating neural network is pre-trained by:
providing a training video of a training talking person and a training image of the training talking person, wherein the training video comprises a plurality of training video frames and a corresponding training audio;
extracting a training acoustic feature from the training audio by the acoustic feature extractor;
generating a plurality of video frames from the training image and the training acoustic feature by the video generation neural network; and
comparing the generated video frames with ground truth video frames using generative adversarial network (GAN), wherein the ground truth video frames correspond to the training video frames.
|